vSAN群集孤立测试
| 服务器 | IP地址 | 说明 |
|---|---|---|
| esxi-6a | MGT:2.2.2.11/24 vSAN:3.3.3.11/24 |
运行VM:RHEL6 |
| esxi-6b | MGT:2.2.2.12/24 vSAN:3.3.3.12/24 |
仅断开vSAN网卡(组件) |
| esxi-6c | MGT:2.2.2.13/24 vSAN:3.3.3.13/24 |
仅断开vSAN网卡(见证) |
| vCenter6 | MGT:2.2.2.10/24 vSAN:3.3.3.10/24 |
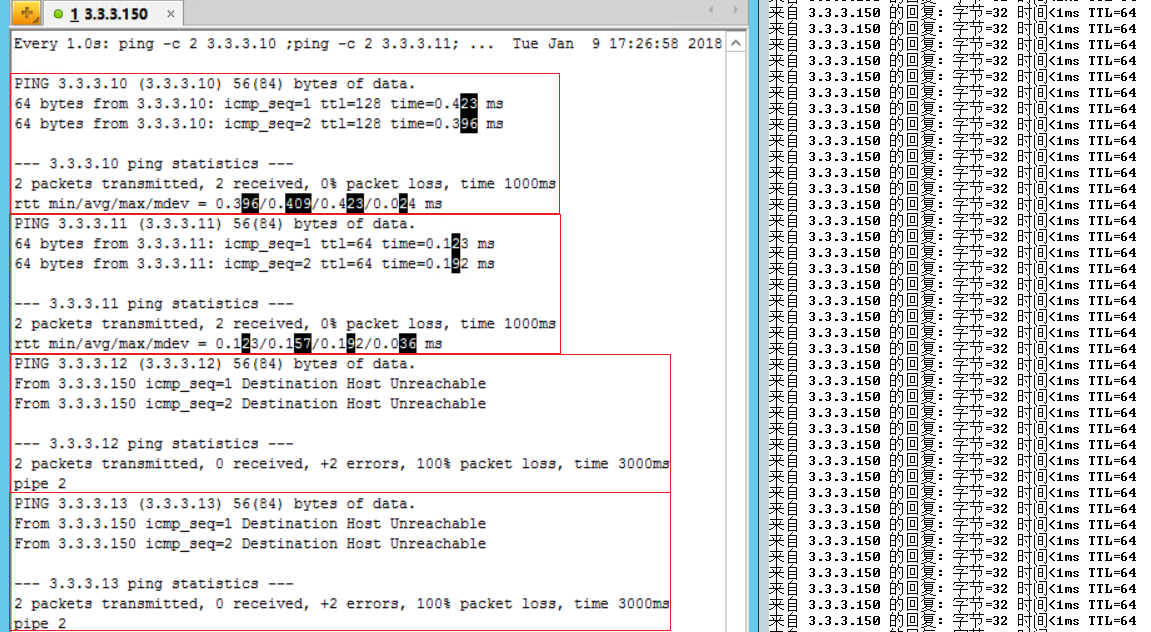
ping 3.3.3.150 |
| RHEL6 | MGT:3.3.3.150/24 | ping 3.3.3.{10,11,12,13} vsan存储策略:允许的故障数(1),磁盘带数(3),容错方法(RAID-1) |
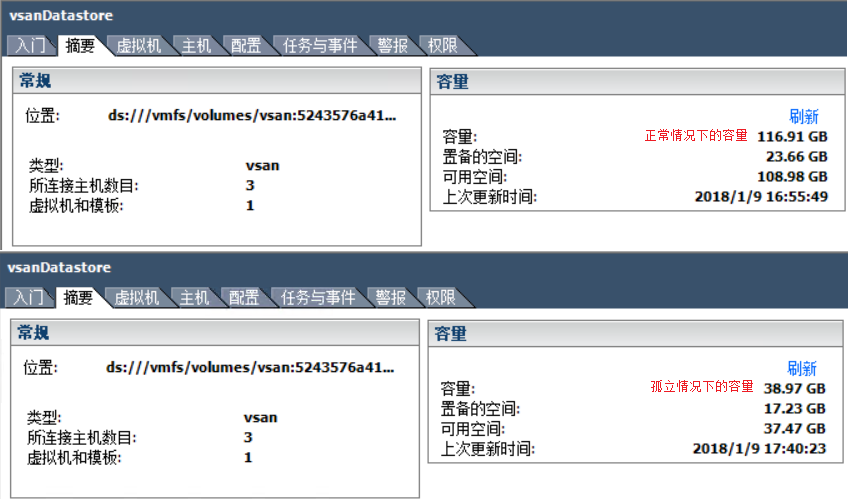
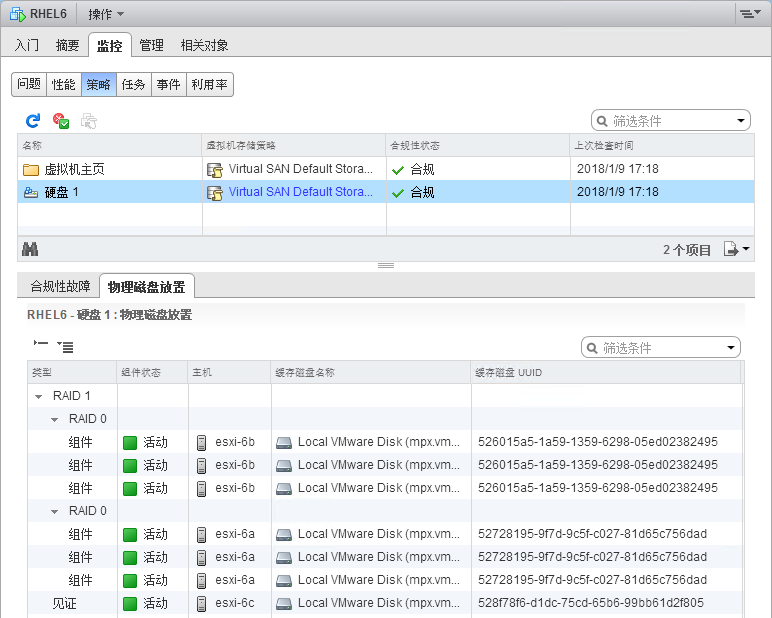
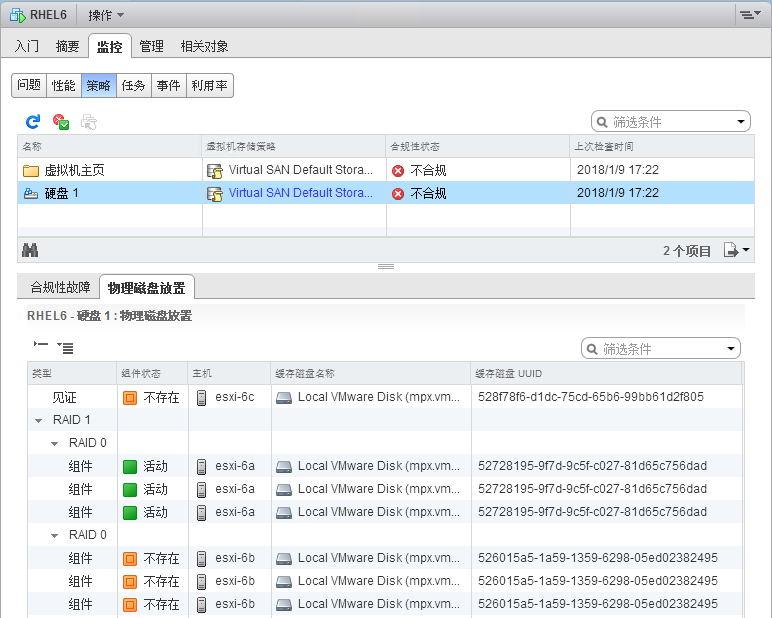
测试结果:ping测试访问RHEL6虚拟机正常,vsan存储器容量减小;ping测试正常但是 du、df 等数据检索命令无法执行(内核缓存运行),当恢复任意1台宿主机vSAN网卡时命令执行正常;会执行HA故障切换。
附加测试:当VM运行在见证服务器上、断开2台组件服务器的vSAN网络,结果同上但不会执行HA故障切换。
简述vSAN群集脑裂
- 在ESX/ESXi 4.x版本中,当群集中主机A的管理网络异常断开,会触发“脑裂”情况、出现虚拟机故障切换;由于vCenter不能与主机A正常通信、触发故障切换(vSphere HA),接管主机B与主机A在争夺虚拟机票据,导致虚拟机不断的开机/关机。
- 在ESXi 5.x/6.x版本中,增加了“数据存储检测信号”,vCenter会在与主机A通信异常的情况下使用数据存储来监控主机和虚拟机。
- 在vSAN群集中,不会启用HA配置中的“数据存储检测信息”;在更改主机A的vsan流量网卡IP地址时,会触发“脑裂”情况、出现虚拟机故障切换;所以在vsan群集中需要调整vsan流量网卡IP地址时、先关闭vSphere HA功能。
- 规划:vSphere HA环境下,为每个vSwitch至少配置2块物理网卡、并且2块物理网卡分别连接在不同网络交换机上。
解决inaccessible问题
现象描述:vSAN运行状况检查出现Virtual SAN对象运行状况“失败”,inaccessible数字为1;
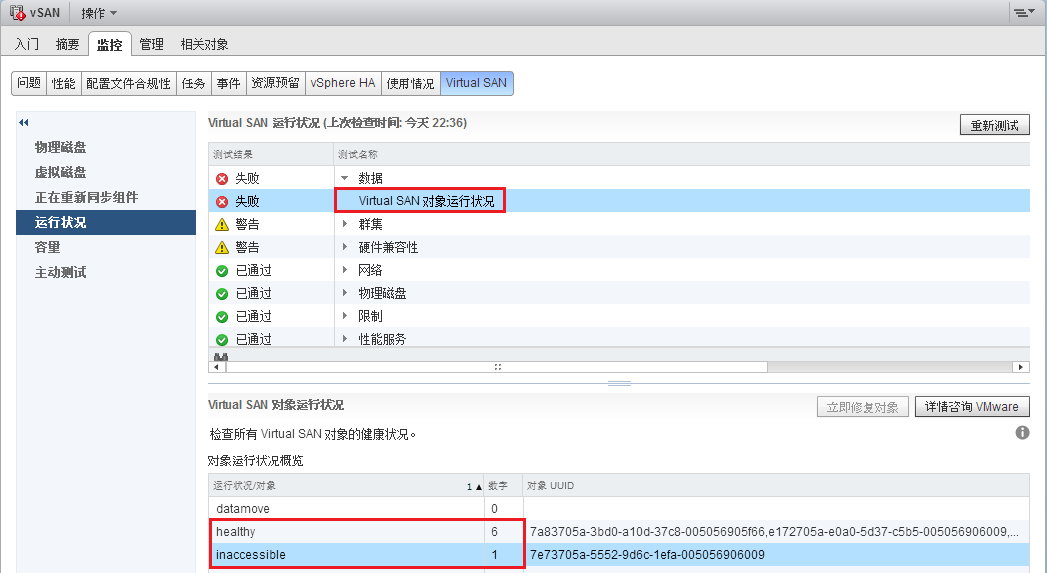
处理过程:
- 在vCenter服务器上运行CMD并连接到RVC(Ruby vSphere Console),在RVC控制台下进入vCenter的HOST目录下,执行命令:
cd "C:\Program Files\VMware\vCenter Server\rvc"
rvc administrator@localhost
vsan.check_state 0
vsan.purge_inaccessible_vswp_objects 0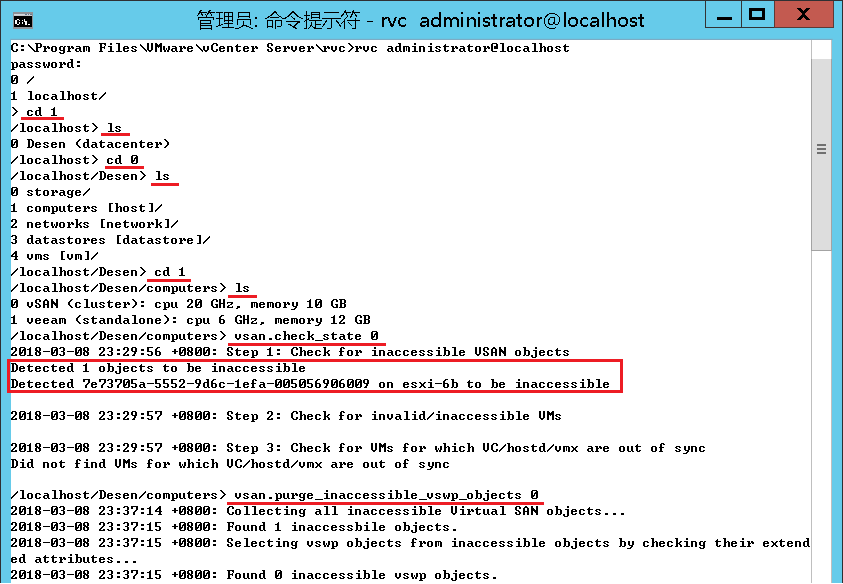
- 通过SSH登陆到相应的HOST(esxi-6b),执行命令:
/usr/lib/vmware/osfs/bin/objtool getAttr --bypassDom -u 7e73705a-5552-9d6c-1efa-005056906009 -c
/usr/lib/vmware/osfs/bin/objtool delete -u 7e73705a-5552-9d6c-1efa-005056906009 -f -v 10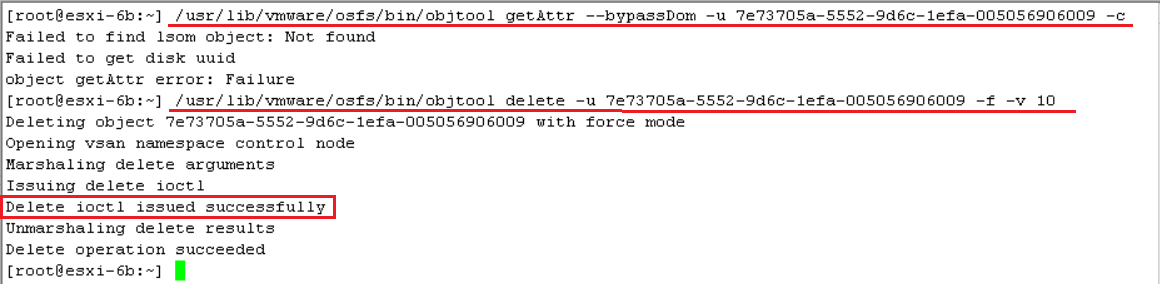
查看VM运行时的内存开销
- 要打开虚拟机电源,需要一定数量的可用开销内存。您应当了解此开销量。
- 虚拟机所需的开销内存量取决于多种因素,其中包括 vCPU 数量和内存大小、设备数量和类型、监视器使用的执行模式以及虚拟机的硬件版本。您使用的 vSphere 版本也可以影响所需的内存量。VMX 将自动计算虚拟机所需的开销内存量。
- 要了解特定配置所需的开销内存量,请先打开相应虚拟机的电源。在 vmware.log 文件中查找。打开虚拟机电源后,所需的开销内存量会打印到该日志。在该日志中搜索 VMMEM 以查看为虚拟机预留的初始和精确开销内存量。
解决vSAN运行状况异常
- “Host not updated to 6.0 U2 or later version. Health Checks disabled.”
- 参考:https://communities.vmware.com/thread/581453
- 说明:重启vSAN群集中单台ESXi主机的vsanmgmtd服务,可能会导致其他运行状况异常;必要时、将vSAN群集中所有ESXi主机的vsanmgmtd服务重启。
- 操作:
/etc/init.d/vsanmgmtd status
/etc/init.d/vsanmgmtd restart
嵌套vSAN环境添加磁盘组时报错
错误信息:vSAN群集主机添加第2组磁盘组时报错“Unable to create LSOM file system for VSAN disk”.
解决方法:为vSAN群集主机添加系统内存,建议不少于32GB。
将vSAN群集主机置于维护模式
官方文档:将 Virtual SAN 群集的成员置于维护模式
其他说明:
- 使用 vSphere Client 将 vSAN 主机进入维护模式时,默认选项为“确保可访问性”;
- vSAN 主机断开连接超过 1 小时后,虚拟机 VMDK 会重新应用关联的存储策略来重构数据。
所以要确保 vSAN 存储器可用容量大于:S * (N/C)
C = vSAN 群集磁盘组总数量
N = 进入维护模式的 vSAN 主机磁盘组数量
S = vSAN 存储器总容量
vCenter性能数据采集
[vCenter Server 设置 --> 统计信息]
| 间隔时间 | 保存时间 | 统计级别 |
|---|---|---|
| 20 秒 | 1 小时 | 实时 |
| 1~5 分钟(默认值5) | 1~5 天(默认值1) | 1~4(默认值1) |
| 30 分钟 | 1 周 | 1~4(默认值1) |
| 2 小时 | 1 个月 | 1~4(默认值1) |
| 1 天 | 1~5 年(默认值1) | 1~4(默认值1) |
Debug
案例:vSAN群集中的ESXi升级小版本从6.0 u2 升级到 6.0 u3后无法识别HDD容量
- 描述:
- 在vClient上将需要升级的ESXi主机进入到维护模式并使用默认选项“将关闭电源和挂起的虚拟机移动到群集中的其他主机上”;
- 使用ISO镜像离线升级并重启,在初始化SSD的时候由于等待时间过长(大概20多分钟)强制重启服务器后;
- ESXi 由 u3 降为 u2(升级后首次启动失败自动回退到旧版本),又在初始化SSD过程中卡了很久;
- 强制重启并重新升级 ESXi 版本到 u3;
- 耐心等待初始化SSD(将近半小时);
- 该ESXi上的所有HDD磁盘无法识别容量。

- 建议:
- 使用Web Client将ESXi进入到维护模式并使用默认选项“将关闭电源和挂起的虚拟机移动到群集中的其他主机上”及“不迁移数据”的vSAN选项;
- 初始化SSD过程中不要强制重启服务器,耐心等待系统开机;
- 可以考虑关闭vSAN环境上的VM,关闭vSAN群集中所有ESXi来同步升级;
- 升级前确保vSAN群集中的所有VM已完成数据备份,特殊情况下可以使用备份数据来重建vSAN群集。
- 解决(临时):
- 由于ESXi识别HDD异常,后台SSH使用dd命令无法完成HDD磁盘I/O操作(无法清除分区表);
- 将故障磁盘组移除并且“不迁移数据”,可以通过Web Client查看SSD和HDD分区表信息;
- 使用Windows/Linux系统安装光盘引导,删除SSD和HDD分区表(vSAN磁盘正常情况显示可用容量为0);
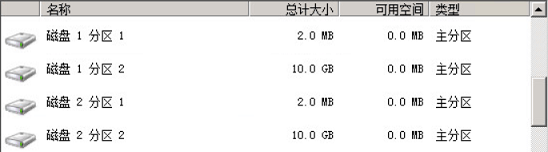
- 重启ESXi主机后可以正常识别HDD磁盘容量,重新添加磁盘组到vSAN群集;
- 比对ESXi主机磁盘型号:
esxcli storage core device list | grep Model
- 解决(永久):
- 由于Lenovo服务器BIOS设置中Boot Modes启用了Optimized Boot选项导致的、改为Disabled后上述问题解决,具体问题联想未给出官方回复。
- Lenovo xSystem M5服务器SD卡做RAID 1某些情况下SD卡控制器异常导致无法被系统加载,可以在IMM--> Local Storage--> SD Configuration--> Controller Actions--> Reset Controller 来重启SD卡控制器。
- Lenovo xSystem M5服务器面板Drive 9设备故障,由于IMM上将2张SD卡作为单独存储器、又组成SDRAID,IMM与BIOS配置未同步(IMM日志无报警而面板报警);断电重开机、必要时将2张SD卡拔插再开机。正常情况下SDRAID为Drive 1设备。
案例:ESXi 6.0 物理 vSAN 环境中嵌套 ESXi 6.5 虚拟 vSAN 环境,由于物理 vSAN 环境使用的存储策略 FTT=0 并且正在执行重平衡作业,此时执行虚拟 vSAN 环境创建磁盘组时提示 “Failed to reserve disk *** error code: -1” 的错误。
- 解决:
- 在物理 vSAN 环境下将虚拟 vSAN 的主机迁移到本地存储器、不关联存储策略;
- 在虚拟 vSAN 环境下重新配置 vSAN 磁盘组;
- 报错原因可能与物理 vSAN 环境的重平衡作业有关,重平衡过程中涉及数据迁移、但是虚拟机数据没有副本(FTT=0)。猜测是为了避免数据不一致而锁定了相关的 vSAN 对象,从而虚拟 vSAN 主机的磁盘无法写入数据。
文章出自: 本站技术文章均为原创,版权归 "Desen往事 - 个人博客" 所有;部分图片来源于 Yandex ,转载本站文章请注明来源。
本文标题:VMware vSAN 应用测试
学习一下inaccessable解决方法
不错,解决了我的问题
正好同样的问题,感谢分享。
感谢分享。
不错,解决了我的问题
学习一下inaccessable解决方法